Transfer Learning: Zakaj AI ne začne od ničle
Predstavljajte si, da bi morali vsakič, ko se učite novega jezika, začeti popolnoma od začetka — brez uporabe znanja slovnice, strukturiranega razmišljanja ali izkušenj iz maternega jezika. Absurdno, kajne? Prav to je razlika med tradicionalnim strojnim učenjem in prenosnim učenjem (transfer learning) v umetni inteligenci.
Kaj je prenosno učenje?
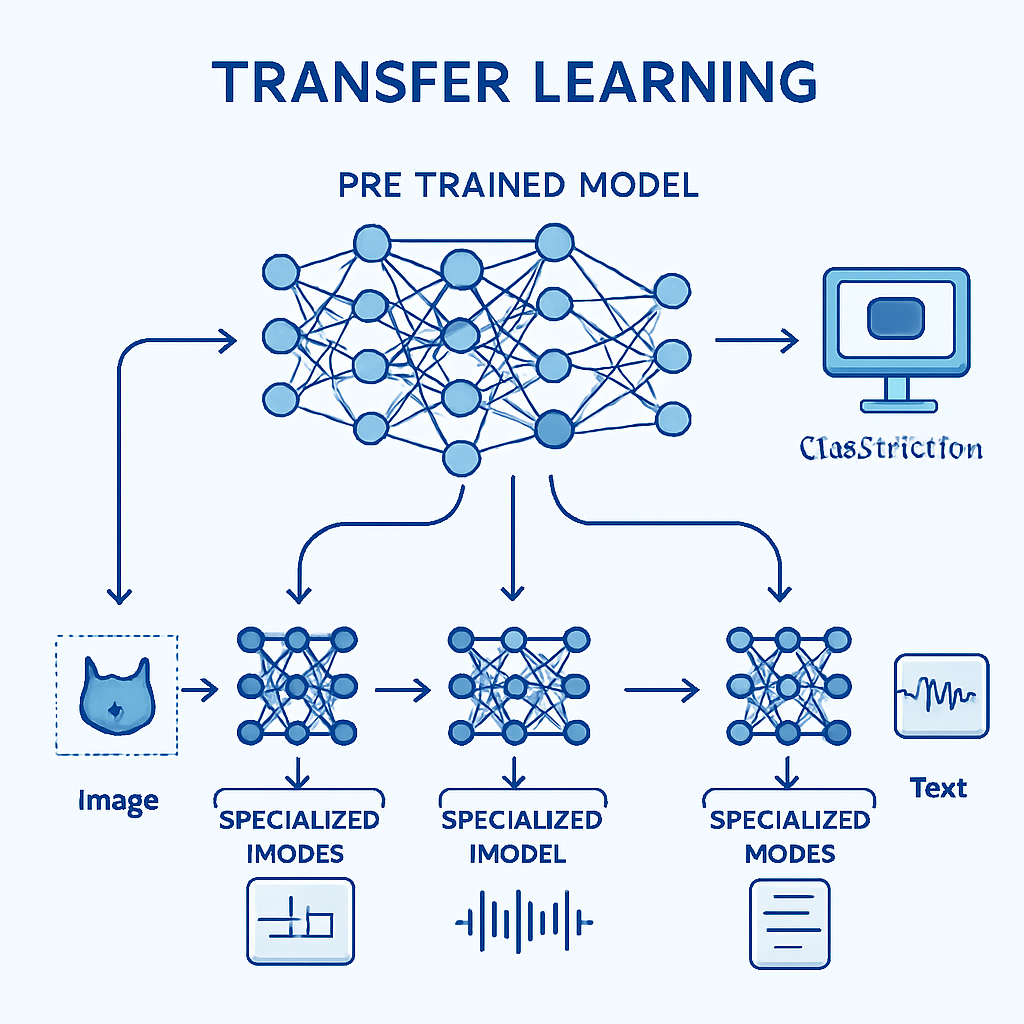
Prenosno učenje je pristop v strojnem učenju, kjer model, ki je bil naučen na eni nalogi, prenese svoje znanje na drugo, povezano nalogo. Namesto da bi za vsak problem gradili AI model od ničle in porabili ogromne količine podatkov ter računske moči, izkoristimo že naučene vzorce in reprezentacije.
V praksi to pomeni, da model, ki se je na milijonih ali celo milijardah podatkovnih točk naučil prepoznavati osnovne vzorce, lahko to znanje uporabi za reševanje specifičnih problemov z bistveno manj podatki. To je revolucija, ki je umetno inteligenco naredila dostopno tudi manjšim podjetjem in raziskovalnim skupinam.
Zakaj je transfer learning ključen za demokratizacijo AI?
Tradicionalno usposabljanje globokih nevronskih mrež zahteva:
- Ogromne količine podatkov: Pogosto milijone označenih primerov
- Izjemno računsko moč: Tedne ali mesece učenja na najzmogljivejši strojni opremi
- Visoke stroške: Več deset tisoč evrov za en sam model
- Specializirano znanje: Strokovnjake za globoko učenje in optimizacijo modelov
Prenosno učenje te ovire dramatično zmanjša. Podjetje ali raziskovalec lahko vzame predučeni model (kot je GPT, BERT, ResNet ali drugi) in ga s samo nekaj sto ali tisoč primeri prilagodi za svojo specifično nalogo. Namesto mesecev učenja zadostuje nekaj ur ali dni, namesto desetin tisočih evrov pa včasih le nekaj evrov računske moči.
Prav ta dostopnost je razlog, zakaj je AI danes prisotna v toliko aplikacijah — od avtomatiziranega ustvarjanja vsebin do medicinskih diagnostičnih sistemov.
Kako deluje prenosno učenje?
Globoke nevronske mreže učijo hierarhične reprezentacije podatkov. Pri obdelavi slik npr. spodnji sloji prepoznavajo osnovne črte in robove, srednji sloji oblike in teksture, zgornji sloji pa kompleksne objekte in koncepte.
Te temeljne reprezentacije so presenetljivo univerzalne. Model naučen na ImageNet podatkovni množici (14 milijonov slik v 1000 kategorijah) razvije sposobnost prepoznavanja robov, tekstur in oblik, ki so koristne pri praktično vseh problemih računalniškega vida — od prepoznavanja defektov v proizvodnji do medicinske diagnostike.
Feature extraction: uporaba naučenih značilnosti
Prvi pristop k prenosnemu učenju je ekstrakcija značilnosti (feature extraction). Pri tem pristopu:
- Vzamemo predučeni model in "zamrznemo" večino njegovih slojev
- Odstranimo zadnji klasifikacijski sloj
- Dodamo nove, naključno inicializirane sloje za našo specifično nalogo
- Učimo samo te nove sloje, medtem ko ostali sloji ostanejo nespremenjeni
To je idealno, ko imamo zelo malo podatkov (morda le nekaj sto primerov) ali ko je naša naloga podobna tisti, na kateri je bil model prvotno učen.
Primer iz prakse: Dermatolog želi razviti sistem za prepoznavanje kožnih sprememb iz fotografij. Namesto da bi zbral milijone medicinskih slik, lahko uporabi ResNet model (učen na splošnih slikah) kot ekstraktor značilnosti in na vrh doda samo majhen klasifikator, učen na nekaj tisoč primerih kožnih lezij.
Fine-tuning: fina prilagoditev celotnega modela
Drugi, naprednejši pristop je fina prilagoditev (fine-tuning):
- Začnemo s predučenim modelom
- "Odmrznemo" nekaj zgornjih slojev (ali celo vse)
- Ponovno učimo model na naših podatkih z zelo nizko hitrostjo učenja
- Model se postopno prilagodi novi nalogi, pri čemer ohrani koristno znanje iz prvotnega učenja
Fine-tuning je močnejši pristop, ki omogoča globlje prilagajanje, vendar zahteva več podatkov (tisoče do deset tisoč primerov) in večje tveganje preučenja (overfitting).
BERT in revolucija v obdelavi slovenskega jezika
Eden najbolj vplivnih primerov prenosnega učenja v obdelavi naravnega jezika je BERT (Bidirectional Encoder Representations from Transformers). BERT je bil učen na ogromnih količinah angleškega besedila z nalogo napovedovanja manjkajočih besed v stavkih.
Za slovenska podjetja in raziskovalce je bila ključna ugotovitev, da lahko večjezični BERT (mBERT), učen na 104 jezikih hkrati, uspešno prenese jezikovno znanje tudi na slovenščino — jezik z relativno malo digitalnih virov.
V praksi to pomeni:
- Razvrščanje besedil: Analiza sentimenta, kategorizacija novic, filtriranje spama
- Named Entity Recognition: Prepoznavanje imen oseb, krajev, organizacij v besedilu
- Question Answering: Sistemi za odgovarjanje na vprašanja v slovenščini
- Generiranje besedil: Platforme kot 1984 uporabljajo napredne jezikovne modele za ustvarjanje kakovostnih slovenskih vsebin
Brez prenosnega učenja bi razvoj tovrstnih sistemov za slovenščino zahteval milijone označenih slovenskih primerov, kar bi bilo praktično neizvedljivo.
Praktični primeri iz industrije
Medicinska diagnostika
Radiologi v slovenskih bolnišnicah lahko uporabljajo modele, predučene na ImageNet, za odkrivanje anomalij na rentgenskih posnetkih ali CT-skaniranih slikah. Model, ki se je naučil prepoznavati teksture in oblike na splošnih fotografijah, uspešno prenese to znanje na medicinske slike — tudi če je na voljo le nekaj tisoč označenih medicinskih primerov.
Nadzor kakovosti v proizvodnji
Slovensko proizvodno podjetje lahko z le nekaj sto fotografijami defektnih izdelkov (razpoke, napake v barvi, nepravilnosti) nauči sistem za avtomatsko kontrolo kakovosti. Osnova je predučeni model računalniškega vida, ki se nato s fine-tuningom prilagodi specifičnim defektom.
Obdelava dokumentov
Podjetja, ki se ukvarjajo z digitalizacijo in obdelavo slovenskih dokumentov, uporabljajo predučene jezikovne modele za:
- Ekstrahiranje strukturiranih podatkov iz neformalnih besedil
- Povzemanje dolgih dokumentov
- Prevajanje strokovne terminologije
- Avtomatsko kategorizacijo in arhiviranje
Praktični nasveti za uporabo transfer learninga
1. Izberite pravi predučeni model: Če delate s slikami, uporabite modele učene na ImageNet (ResNet, EfficientNet, Vision Transformer). Za besedila izberite BERT, GPT ali druge jezikovne modele.
2. Začnite s feature extraction: Če imate malo podatkov (pod 1000 primerov), začnite z zamrznitvijo večine slojev in učenjem samo klasifikatorja.
3. Postopno odmrzujte: Če rezultati niso zadovoljivi, postopoma odmrznite zgornje sloje in jih fina-prilagodte z nizko hitrostjo učenja.
4. Uporabite data augmentation: Tudi pri prenosnem učenju velja — več (raznolikih) podatkov pomeni boljši model. Uporabite tehnike povečevanja podatkov specifične za vašo domeno.
5. Spremljajte preučenje: Z manjšimi podatkovnimi množicami je tveganje overfittinga višje. Uporabljajte validacijsko množico in tehnike regularizacije.
Prihodnost prenosnega učenja
Najnovejši trendi kažejo na še bolj učinkovite pristope:
Few-shot learning: Modeli, ki se lahko prilagodijo novi nalogi z le nekaj primeri (včasih celo brez dodatnega učenja)
Zero-shot learning: Sposobnost modela, da izvede nalogo, ki je nikoli ni videl med učenjem, samo na podlagi besedilnega opisa
Multi-task learning: Modeli, ki se hkrati učijo več nalog in prenašajo znanje med njimi
Domain adaptation: Napredne tehnike za prenos znanja med zelo različnimi domenami
Zaključek: AI za vsakogar
Prenosno učenje je tehnologija, ki je umetno inteligenco naredila dostopno vsem — od raziskovalcev in razvijalcev do podjetij in posameznikov. Namesto da bi vsak začel od ničle, lahko gradimo na ramenih velikanov — modelov, učenih na milijardah podatkovnih točk.
Če želite izkusiti moč naprednih AI modelov brez potrebe po globokem tehničnem znanju, preizkusite platformo 1984 — slovensko rešitev za ustvarjanje kakovostnih vsebin z umetno inteligenco. Naši modeli uporabljajo najnovejše pristope prenosnega učenja, prilagojene slovenskemu jeziku in kulturnem kontekstu.
Čas je, da tudi vaše projekte poženete z AI tehnologijo. Začnite danes — brez milijonov podatkov, brez mesečnega čakanja, brez začenjanja od ničle.